A More Detailed Explanation
Uncertainty is ubiquitous. Any representation scheme intended to model real-world actions and processes must be able to cope with the effects of uncertain phenomena.
A major shortcoming of existing Semantic Web technologies is their inability to represent and reason about uncertainty in a sound and principled manner. This not only hinders the realization of the original vision for the Semantic Web, but also raises an unnecessary barrier to the development of new, powerful features for general knowledge applications.
The overall goal of our research is to establish a Bayesian framework for probabilistic ontologies, providing a basis for plausible reasoning services in the Semantic Web. As an initial effort towards this broad objective, this dissertation introduces a probabilistic extension to the Web ontology language OWL, thereby creating a crucial enabling technology for the development of probabilistic ontologies.
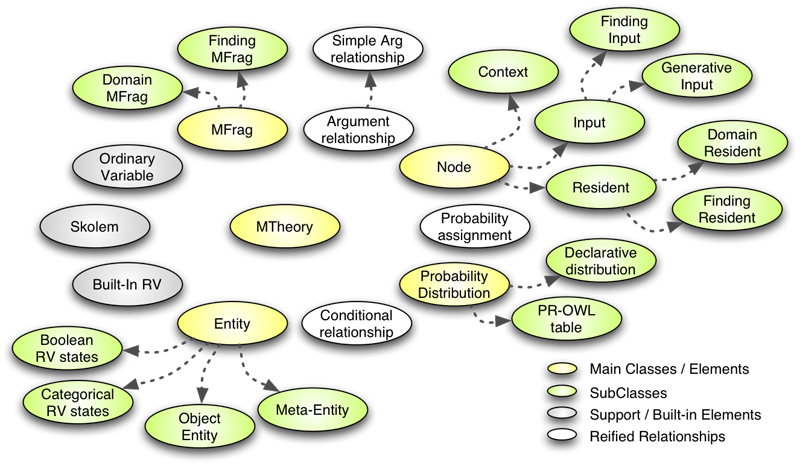
The extended language, PR-OWL (pronounced as "prowl"), adds new definitions to current OWL while retaining backward compatibility with its base language. Thus, OWL-built legacy ontologies will be able to interoperate with newly developed probabilistic ontologies. PR-OWL moves beyond deterministic classical logic (Frege, 1879; Peirce, 1885), having its formal semantics based on MEBN probabilistic logic (Laskey, 2008).
By providing a means of modeling uncertainty in ontologies, PR-OWL will serve as a supporting tool for many applications that can benefit from probabilistic inference within an ontology language, thus representing an important step toward the World Wide Web Consortium's (W3C) vision for the Semantic Web.
In addition, PR-OWL is suitable for a broad range of applications, which includes improvements to current ontology solutions (i.e. by providing proper support for modeling uncertain phenomena) and much-improved versions of probabilistic expert systems currently in use in a variety of domains (e.g. medical, intelligence, military, etc).
Current Status
The first seed of PR-OWL began to grow in Paulo Costa's PhD Dissertation and it is currently a work in progress. Today, there are two teams working on paralel. The first team is headed by Prof. Kathryn B. Laskey, at George Mason University'' C4I Center, which a focus on the semantics and logical framework underlying the language. The second team has a focus on developing a MEBN reasoner for PR-OWL, based on the already successfull Bayesian Network package UNBBayes, an open source project led by Prof. Marcelo Ladeira, at the University of Brasilia.
How to use this site?
The website is a collection of pages designed to help people to understand the concept of a Bayesian ontology language as it is being developed. In addition to the pages directly related to PR-OWL, there is a substantial amount of pages conveying background information, including probability theory, Bayesian Networks, Web Languages, MEBN and others. Also, you will find references to most of the work cited in the pages (usually in the bottom of each page), and links to relevant sources of information.
Beginning in November 2006, we started a major overhaul of the PR-OWL web site, fulfilling an old pledge for transforming it from a simple repository of papers and references to an actual tool for researchers and other people interested in our work. However, due to extreme overload we failed to update the site as fas as we would like to and it stayed most of the years 2008 to 2010 unchanged. Now, starting from December 2010 we will be resuming the site construction and expect to reach a final configuration by July 2011.
We hope visiting our site becomes an enjoyable and useful experience, and encourage you to send feedback on how we might improve it.
Thanks!